
How to Boost Your DevOps Team's Performance with a Few Simple Moves
Finding Money in DevOps
Waste is a consideration in any business process. In DevOps processes, waste typically falls under common areas:
- Project Error: Errors in new engineering projects. (often from design/estimation errors)
- Operational Toil: Repetitive work done by humans that could be automated, reduced or removed.
- Under-optimized Deployments: When existing processes can do more for less.
This post will primarily focus on under-optimized deployments. Pragmatism dictates that we describe the opportunity first and then talk about the decision process to maximize the opportunities' value.
Identifying Opportunities
Background
For our products (including g5), frameworks and internal tools we continuously build, test and deploy over 40 pipelines.
In this context, what is a pipeline?
PIPELINE : Something useful (or which is used) to the business.
PIPELINE IOW:
- code -> build -> test -> release -> deploy
- A pipeline refers to the steps needed to assemble, test and deploy a given product, service or software component.
- A pipeline can also be thought of as a single output, typically a product, service or package.
- Pipelines can use pipelines (upstream) and in turn be used by other pipelines (downstream).
As pipelines use each other for fundamental business purposes, a related group of pipelines is often referred to as a value stream (the business value flowing downstream to the ultimate users).
g5 Example
As an example, here's a flowchart of g5's pipeline value stream:
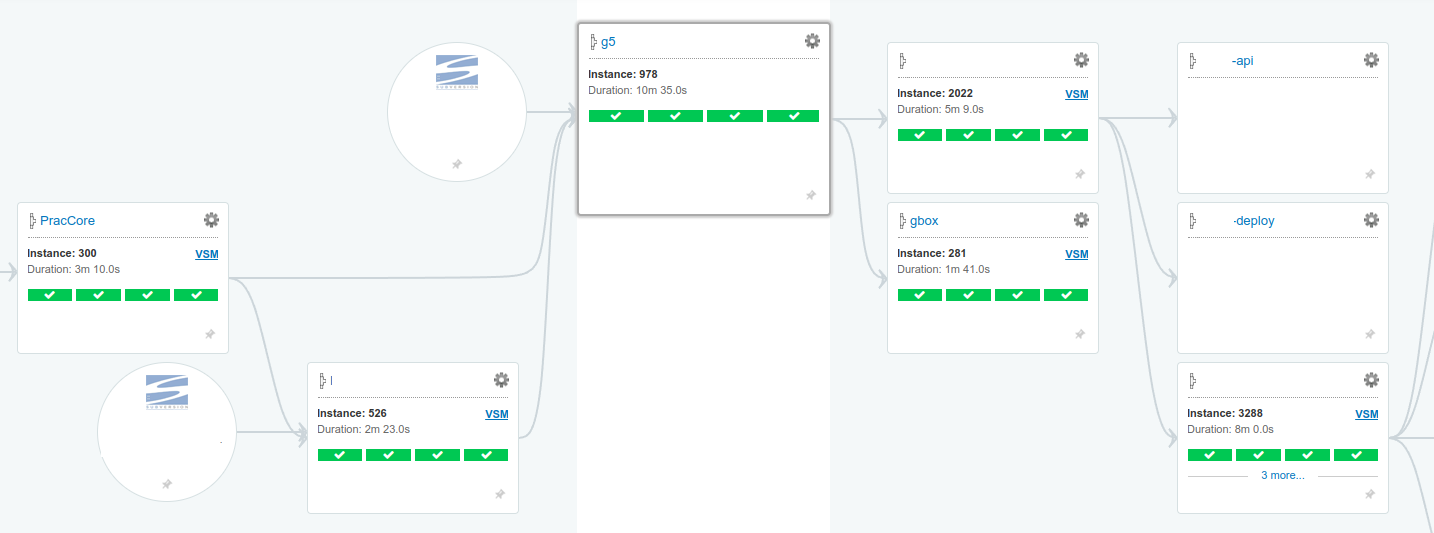
To deploy a product, we have to deploy all the product's upstream pipelines (left side of value stream) then deploy the product.
Product deployments mentioned here are automated and continuous.
When a change is introduced:
- The pipeline with the change is rebuilt, retested, and then redeployed.
- Every downstream/dependent pipeline is similarly rebuilt and redeployed.
So it's automated but not free, every change consumes resources and time.
Deployment times also affect Project Error, because if there is a 1hr lag between a change and it's introduction for the next-level of testing, a developer who fails other developers pipelines may have to push additional fixes, each requiring approximately the same time to wait
While developers don't have to sit on their hands through deployment, the costs of context switching between projects make long lags less than desirable.
Additionally, in our case there are applications which can only promote during certain times of day. So getting in a quick fix can be costly, as the change must be pushed not just in advance of deadline, but also in advance of current lag time. Otherwise the change can get pushed until the next window, resulting in delays that can have big effects on DevOps DORA metrics (i.e. Deployment Frequency and Lead Time).
Here, at the start of q3 our longest running pipelines looked like this:
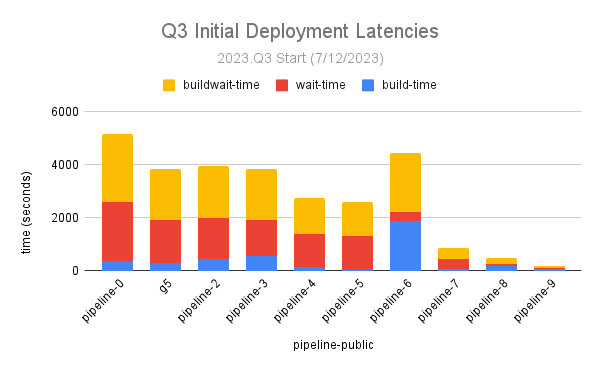
We can see that an internal pipeline- pipeline #6 here- has by far the longest average build time at over 30 minutes. We also notice many of our pipelines spend meaningful time waiting for an acceptable build resource before they can execute.
Relative Degrees of 'Free'
Since the total time to deploy a change to an end-user product is the sum of the upstream pipeline buildwait times, we can reduce our pipeline deployment times in two ways:
- Reduce build times
- Reduce wait times
Lets examine how "free" each approach can be.
Reducing build times
Reducing build times can be accomplished in a number of ways:
- reducing single instance build/test time (eg by removing deprecated code or tests)
- speeding up code that runs in tests
- parallelizing builds so more is built/tested in same time interval
The first two options share in common that those decisions are highly localized to each pipeline and/or codebase. Parallelization is more pareto efficient in that a small change can provide large benefits that are often independent of the pipeline specifics or business cases.
Reducing wait times
Reducing wait times is mostly a function of keeping build agents better utilized. Ways to accomplish wait time reduction include:
- Adding more build hosts
- Making sure that existing build hosts are utilized more fully
It should be noted that reducing build times also reduces wait times.
Freest Money : g5 Example
As reducing wait times is more generalizable, it's usually "cheaper" to reap the freedoms by adding more build hosts. Also since adding more hosts is often a turnkey operation, you can simply buy a faster deploy time in these cases.
In our case this is still true, but it was noticed that because we have different underlying categories of build hosts, some of the build requirements were waiting for a higher class of resource when it should have been able to use a less specific build host. Booting new build-hosts on demand is also an option but this can introduce new forms of waste. Also in our case there was an unknown but likely maximum of how much extra productivity we would be able to utilize right away, so it made sense to get the biggest meaningful bang for our buck and let the rest of our workflows adapt to the new capacity.
Making a few changes to our pipeline infrastructure, allowed us to use approximately the same number of build hosts but wait almost 50% less time for them. This combined with some small but inexpensive changes to reduce individual pipeline work, let us reduce build times a few percent on average and reduce wait times by almost 50% on average.
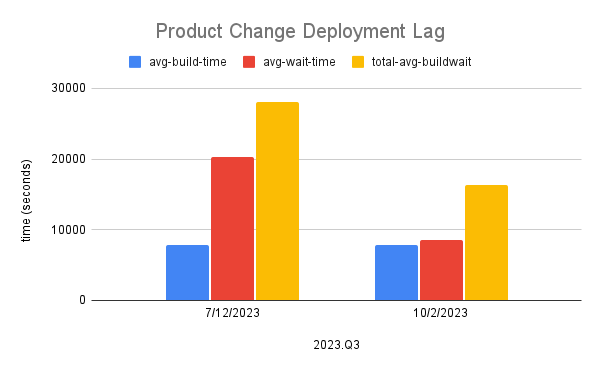
So this has cut maximum average deploy time from almost 4hours to just over 2hrs. With a 4hr lead time, that means you could push two distinct changes maximum in an 8hr day and 10/week. Halving this means increasing the number of things we can try by 2x.
In practice it's more dramatic because most changes aren't to the most upstream pipeline in a value stream, meaning that you're only building and waiting for the downstream pipelines.
We haven't been able to fully realize these benefits yet, but so far we've seen pipeline improvements ranging from 10% to 50% in the number of changes we are deploying each week.
Why It's Worth It
So freeing up DevOps resources doesn't just help maximize developer productivity and focus, at a higher level you've now got more bytes at the apple to hit ALL your business targets (OKRs, KPIs, etc).
